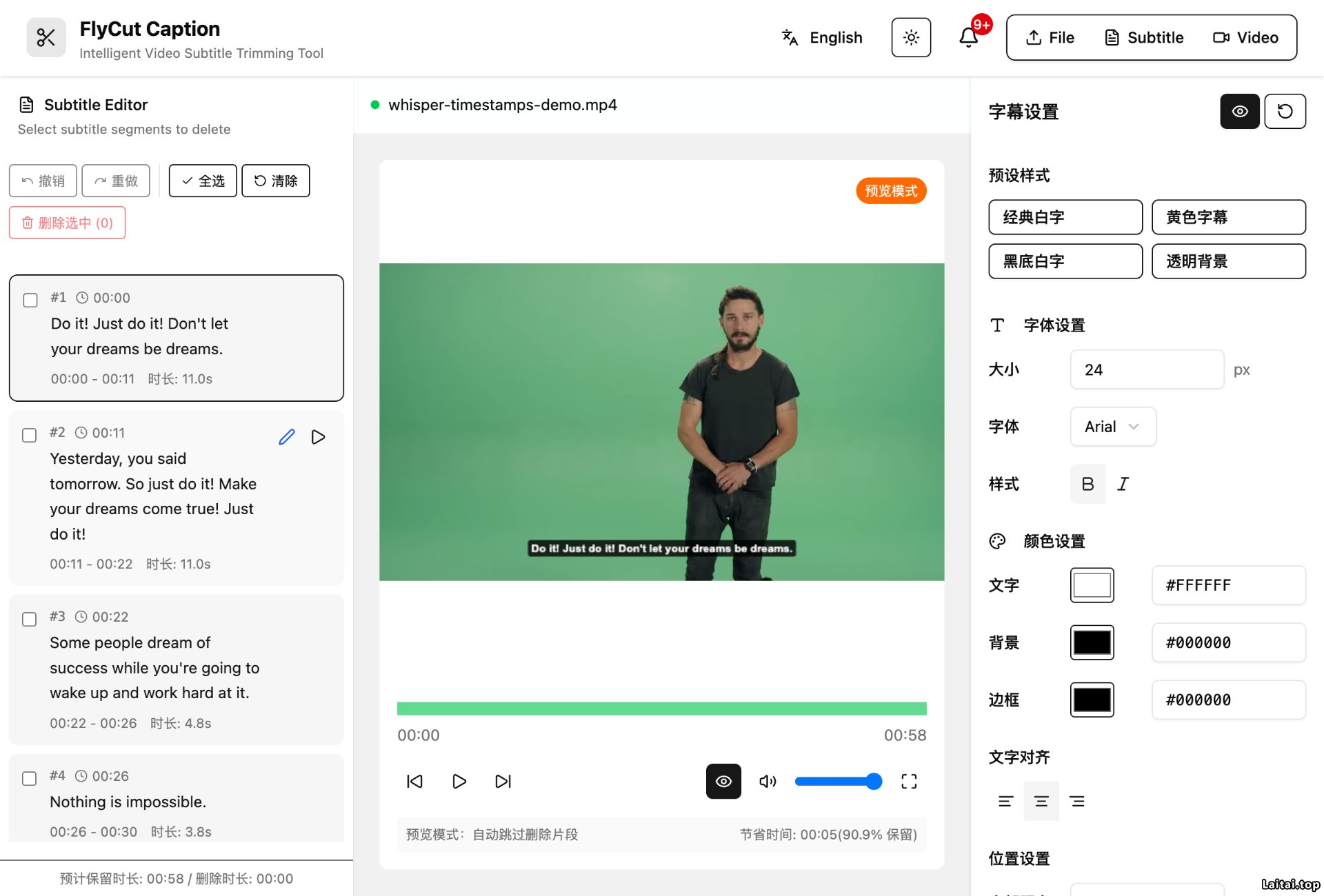
基于 Whisper 模型做语音识别,支持多语言,生成的字幕带时间戳,可以直接在可视化界面里选中删除不要的片段,实时预览效果。
除了字幕编辑,还能自定义字幕样式,包括字体、颜色、位置等,以及支持导出 SRT、JSON 格式,或者直接把字幕烧录到视频里导出成品。
整个处理过程跑在浏览器的后台线程里,不会卡界面,而且提供了 React 组件包,可以直接集成到自己的项目中。
基于 Whisper 模型做语音识别,支持多语言,生成的字幕带时间戳,可以直接在可视化界面里选中删除不要的片段,实时预览效果。
除了字幕编辑,还能自定义字幕样式,包括字体、颜色、位置等,以及支持导出 SRT、JSON 格式,或者直接把字幕烧录到视频里导出成品。
整个处理过程跑在浏览器的后台线程里,不会卡界面,而且提供了 React 组件包,可以直接集成到自己的项目中。